
Considering A W3C Standard For Stateful Serverless
We're Rivet, a new open-source, self-hostable serverless platform with a focus on stateful serverless. If you want to support our mission of building a production-ready and self-hostable serverless runtime, give us a star on GitHub.
Earlier today, I was called upon by Cloudflare's @threepointone and @janwilmake regarding my thoughts on a standard for stateful serverless.
Having implemented a cloud-agnostic stateful serverless library called RivetKit, I have a lot of experience with what's required to build a portable standard. And thus, I derailed my Saturday to write them down here.
This specification is intended as step 1 to start the conversation about what is required to develop a stateful serverless specification that makes stateful serverless easier for companies to adopt. I don't expect this to be the end result. See Specification Goals for more information.
What Is Stateful Serverless?
Unless you're deep in to Cloudflare Durable Objects or Rivet Actors, there's a good chance you've never heard of "stateful serverless."
Stateful serverless allows serverless functions to maintain state across multiple invocations. They're very similar to Web Workers (specifically SharedWorker) on the server and share characteristics with the actor model. The most popular implementation of this today is Durable Objects.
The adoption of stateful serverless is fairly new: Durable Objects was announced 4.5 years ago and only recently saw widespread use over the past couple years.
Stateless Serverless (Functions) vs Stateful Serverless (Workers)
Stateless serverless is what you'd normally think of when you hear "serverless functions." An example implementation on Cloudflare Workers would look like this:
On the other hand, stateful serverless provides an infinitely running process with storage. An example implementation on Rivet Actors would look like this:
Primary Use Cases
The primary use cases of stateful serverless are:
- Long-Running Processes: Tasks that execute over extended periods or in multiple steps. For example, AI Agents with ongoing conversations and stateful tool calls.
- Stateful Services: Applications where maintaining state across interactions is critical. For example, Collaborative Apps with shared editing and automatic persistence.
- Realtime Systems: Applications requiring fast, in-memory state modifications or push updates to connected clients. For example, Multiplayer Games with game rooms and player state.
- Durability: Processes that must survive crashes and restarts without data loss. For example, Durable Execution workflows that continue after system restarts.
- Horizontal Scalability: Systems that need to scale by distributing load across many instances. For example, Realtime Stream Processing for stateful event handling.
- Local-First Architecture: Systems that synchronize state between offline clients. For example, Local-First Sync between devices.
Read more about stateful serverless here.
Scope Of This Proposal
For the purpose of this article, we'll assume stateful serverless includes message passing & persistent storage. This means we're not going to consider actor runtimes, such as Erlang/OTP, Akka, Orleans, Actix, and Swift Actors which do not include storage as a core component.
Why Should I Care?
Even if you've never heard of stateful serverless, you're probably using a site on a daily basis that already relies on stateful serverless with technologies like Cloudflare Durable Objects:
- CodePen
- Liveblocks
- Clerk
- Wordware
- Playroom
- Tldraw
Similarly, a significant portion of applications in general are powered by services with the actor pattern, which is a subset of what this standard would provide:
- WhatsApp (notoriously acquired for $19B with Erlang/OTP having only 35 engineers)
- Discord
- Twitter/X
- PayPal
- Halo
- FoundationDB (powering Apple, Snowflake, DataDog)
- Many, many more
Why Build A Web Standard?
Customers Wary Of Vendor-Lock
In 2025, customers are wary of vendor-locking themselves to cloud services. It's common for vendor-locked providers to either shut down, turn out to be unreliable, or price gouge contracts because their customers cannot leave.
Therefore, a standard allows all platforms offering stateful serverless to become a compelling offering. It's a rising tide: more competition means wider adoption and more customers.
For example: though AWS is the leading cloud provider and pushes their own closed-source & non-standard software like DynamoDB & Lambda, they still need to provide standard- and open-source-compatible software like Redis (ElastiCache), Cassandra (Keyspace), and Postgres/MySQL (Aurora) in order to remain an attractive offering for customers concerned about vendor lock.
Incentivize More Providers
A standard would incentivize more cloud providers to enter the stateful serverless space. Currently, only Cloudflare, Rivet, and RivetKit offer this capability, leaving a massive opportunity for other serverless cloud providers to adopt stateful serverless. With a common standard, more frameworks & developers can adopt this model.
Today's Stateful Serverless Implementations
Cloudflare Durable Objects: The Most Popular Option
Today, Cloudflare Durable Objects are the incumbent of stateful serverless cloud providers.
A Durable Object looks something like this:
Cloudflare Agents Framework: Moving Beyond Durable Objects
The Cloudflare Agents framework is for AI-powered agents to operate on the Durable Objects infrastructure.
As stated in their launch blog post:
Over the coming weeks, expect to see ... the ability to self-host agents on your own infrastructure.
Purely theorizing: a standard for stateful serverless might provide the foundation for this.
Rivet: Open-Source Serverless Infrastructure
I'm the founder of Rivet and have a vested interest in seeing stateful serverless become a standard. Rivet provides an open-source stateful serverless platform that can be easily self-hosted.
We also provide a handful of features in our runtime that don't make sense to be part of a standard, since the best W3C standards build on existing web standards: Docker containers for non-JavaScript applications, HTTP, UDP, and TCP support, advanced lifecycle management, actor tagging for advanced multi-tenant applications, advanced control over actor upgrades for companies with specific use cases, fine-grained control over where your actor is running, and a developer-friendly REST API for managing Rivet Actors.
We encourage developers building on Rivet to use RivetKit. However, we also provide a low-level API for defining actors:
Unlike Durable Objects, Rivet's core API design opts to lean into Unix-like patterns such as using SIGINT signals, leveraging process.exit, and using environment variables.
Check out the source code on GitHub.
RivetKit Framework: Stateful Serverless On Any Cloud
At Rivet, we also manage a framework called RivetKit that provides a Durable Object-like experience on any cloud that provides stateless serverless.
A Rivet Actor definition looks something like this:
Under the hood is where it gets interesting: RivetKit is intended to support as many platforms as possible and is completely abstracted with drivers. By doing so, RivetKit supports Rivet, Cloudflare Durable Objects, Bun, Node.js. Vercel, Supabase, Deno, and Lambda are coming in the near future.
These drivers provide a peek at what a standard might require, since they're already abstracted to be platform-agnostic:
ActorDriver: Manages actor state, lifecycle, and persistence
ManagerDriver: Handles actor discovery, routing, and scaling
There is also a CoordinatedDriver that provides support for implementing actors over peer-to-peer for platforms that don't natively support stateful serverless. This would not apply to an actor standard.
Read more about building your own RivetKit drivers.
Check out the source code on GitHub.
Other Actor Runtimes: The Precursor To Stateful Serverless
Runtimes like OTP (i.e. Erlang & Elixir & Gleam), Akka, Orleans, Actix, and Swift Actors all lack built-in support for persisted state. There are libraries that provide state for actors, but their models are significantly different than what we'll consider here. Additionally, we're focused on JavaScript since that's primary language for web standards.
Specification Goals
For the purpose of this exploration, I'm going to recommend sticking with web standards, which are managed by the W3C organization. Doing so allows us to build on top of existing successful web standards, such as WinterTC and the fetch specification that are currently offered across almost all stateless serverless platforms already.
The goals of this proposal are:
- Simplicity Of Implementation: Implementing standards correctly is difficult, expensive, and highly error prone. Simpler is better.
- Simplicity Of Usage: Stateful serverless is not a concept that is easy for many developers to understand. Prefer simplicity vs advanced features to keep the API as simple as possible for greater adoption.
- Build For Frameworks: Hono and itty-router already proved that frameworks are almost always used with serverless runtimes. Stateful serverless is already used widely with PartyKit, RivetKit, Agents, and misc tools like TinyBase. If possible, leave functionality up to frameworks to implement.
- Built On Existing Web Development Paradigms: Stateful serverless is very similar to Web Workers. Where possible refer to Web Workers to see what works well.
- Focus On Stateful Workloads, Not Actors: I love building distributed systems with the actor model, but actors require extra consideration around message handling, concurrency, and backpressure.
Classes vs Functions
Durable Objects provides a class-based approach to stateful serverless (e.g. class X extends DurableObject { ... }). Rivet provides a functional approach (e.g. export default { start () { ... } }).
Sticking to the WinterTC ESM-style makes sense. Additionally, it's similar to how Web Workers are already defined.
Alternative #1: Fetch-Based Communication
Both Rivet & Durable Objects use WinterTC-like fetch handlers to accept requests on Durable Objects/Rivet Actors. An alternative spec would opt to use fetch handlers instead of a brand new definition. This is similar to what WinterTC is attempting to do: take existing patterns and standardize them as opposed to implementing a new standard.
This standard makes an intentional decision to define a simpler, more portable API than provide compatibility with only 2 existing implementations.
Alternative #2: A CGI-Like Standard
An alternative implementation is to consider something along the lines of CGI which provides a more Unix-like implementation of serverless functions & supports multiple languages. However, the industry has consolidated behind JavaScript & WebAssembly for serverless clouds because of the developer & cost efficiency. Additionally, CGI lacks many of the modern features that W3C specifications take into account for web standards. (Originally proposed by Armin Ronacher.)
Drawing Inspiration From SharedWorker
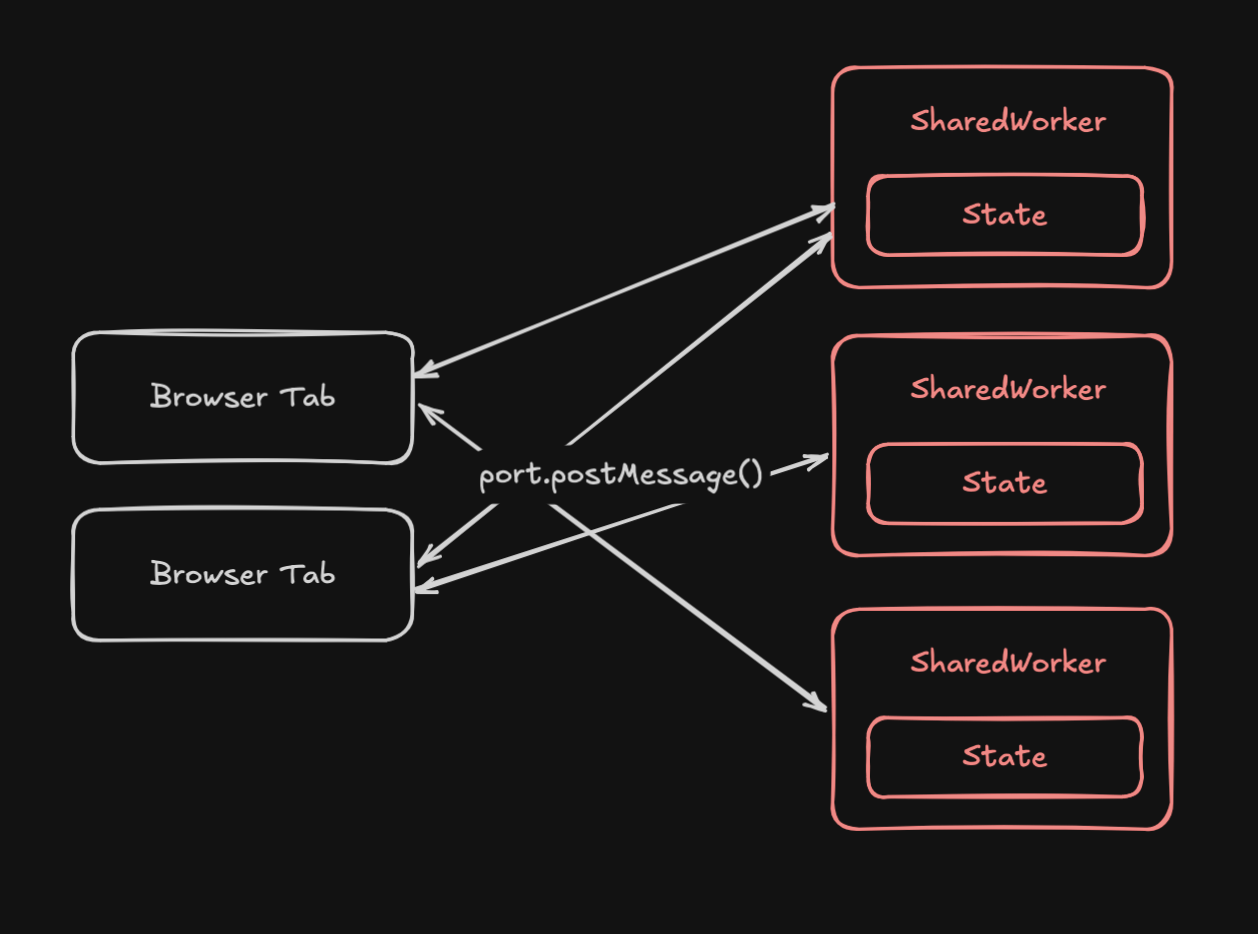
Though designed for client-side concurrency, SharedWorker offers a programming model that closely resembles what we're discussing for server-side actors. The SharedWorker API already has many of the core concepts needed for a stateful serverless standard:
- Multi-Tenant:
SharedWorkercan serve multiple browser tabs, similar to how Durable Objects and Rivet Actors serves multiple clients - Isolated Execution Context: Each worker runs in its own isolated environment
- Message-Based Communication: Workers communicate via structured message passing.
You can think of a ServerlessWorker like a SharedWorker that is:
- In the cloud
- Includes persistent storage
- Runs forever
Here's a comparison of how Web Workers operate in the browser:
The onmessage handler is very similar to the fetch handler in a Durable Object or an Action in RivetKit.
The key differences are:
- Persistence: Web Workers lose state when the page refreshes, while
ServerlessWorkers maintain state between invocations. - Network Access: Stateful serverless inherently supports network requests via fetch/WebSockets.
- Lifecycle Management:
ServerlessWorkers have advanced wake/sleep and scheduling capabilities.
Introducing ServerlessWorker
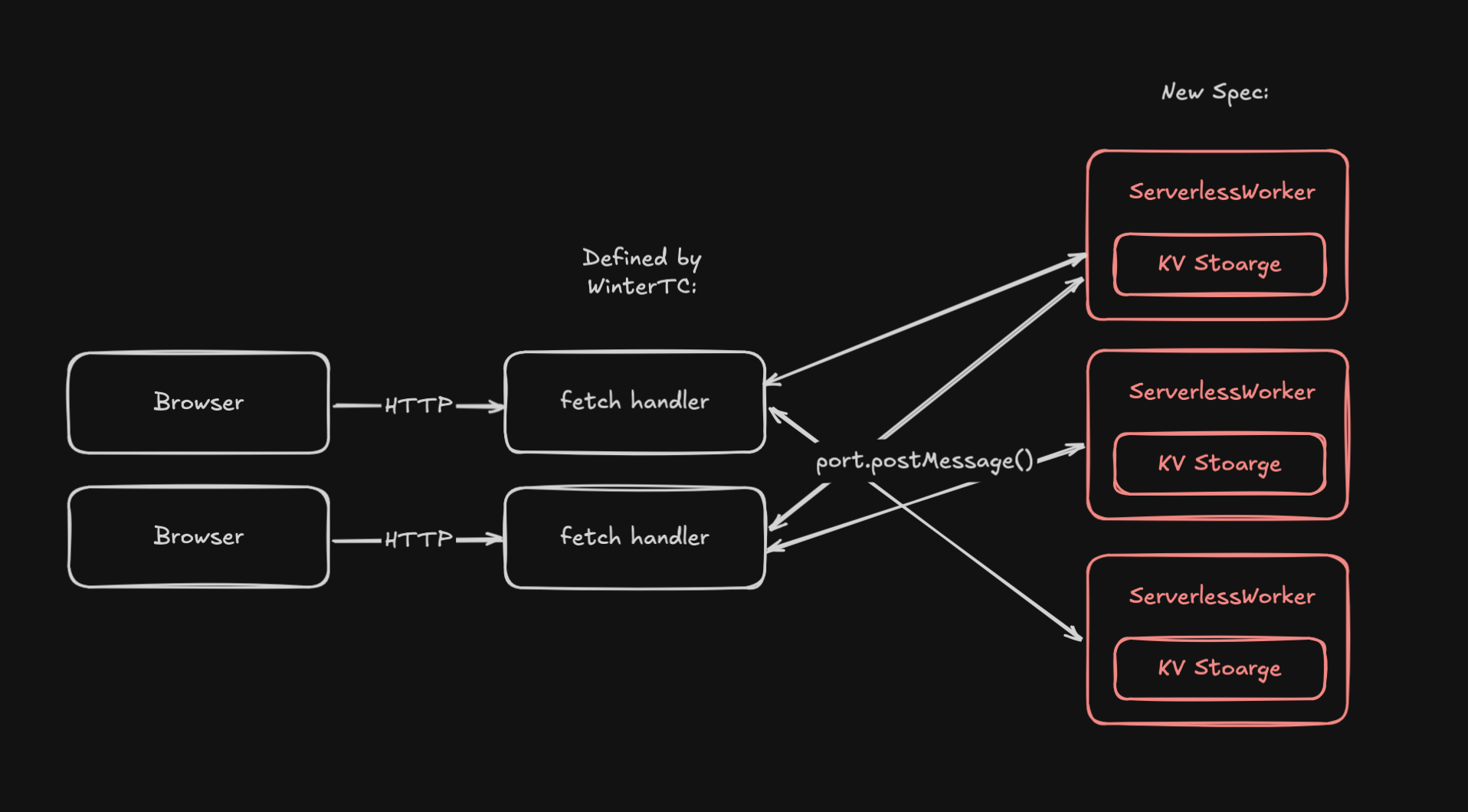
ServerlessWorker is an API similar to the existing Web Workers API that provides the core functionality of both Cloudflare Durable Objects and Rivet Actors:
- Multi-Tenant:
ServerlessWorkercan serve multiple clients at the same time in realtime. - Message-Based Communication: Communicates via
postMessage. - Persistent:
ServerlessWorkersrun forever. They cannot crash. Implementations of the standard can optionally make workers sleep when there is no activity. - Storage:
ServerlessWorkerscan store data that persists for ever. Implementations of the standard should design this data to be stored next to compute for optimal read-write performance. - Isolated Execution Context: Each worker runs in its own isolated environment
Creating, Initializing, & Addressing ServerlessWorkers
Current Implementation: Rivet & RivetKit
Rivet and RivetKit provide a tagging system for organizing actors. This allows you to build more manageable multi-tenant applications with complex requirements. For example:
Rivet allows you to create actors with the actors.create endpoint. The API accepts environment variables to configure how the actor behaves.
RivetKit allows passing tags to client.get({ /* tags */ }) to get or create an actor, but does not provide environment variables. You can also use the client.create method to create a fresh actor. Actors can read their own tags to configure behavior accordingly:
Current Implementation: Durable Objects
To create a Durable Object on Cloudflare, you call the newUniqueId method. This will give you a unique ID for a new Durable Object.
Cloudflare also provides a idFromName method to get the ID of an Durable Object from an arbitrary string. This ID is then used to resolve a Durable Object stub that you can send requests to. For example:
Cloudflare Durable Objects is desigend to have no concept of "created" or "destroyed." The initial state can be configured by sending an RPC to the DO upon creation. This implementation of not having an input state for a ServerlessWorker is simpler and leaves the functionality up to the framework; instead all a ServerlessWorker has a unique ID that developers can send messages to.
Current Implementation: SharedWorker
SharedWorker accepts a name parameter, for example: new SharedWorker("./sharedWorker.js", chat-room-random). This is akin to calling idFromName for Durable Objects. Passing no name will give you the same worker.
The name is accessible in the global scope of the SharedWorker.
Proposal
Constructing a ServerlessWorker object will mimic the SharedWorker API. Passing a name parameter to the second constructor argument will let you address a given ServerlessWorker. Passing no arguments will give you the same worker.
The name is accessible in the global scope of the ServerlessWorker.
An example API could look like:
To resolve with a custom name:
To access the name in the worker:
Terminating ServerlessWorkers
Current Implementation: Rivet
Rivet provides two ways to destroy an actor: use process.exit(0) or call actors.destroy from the API.
RivetKit will provide a ctx.shutdown method that delegates to ActorDriver, though is not currently implemented.
Current Implementation: Durable Objects
Cloudflare's approach to destroying Durable Objects is somewhat unique. There is no concept of "created" or "destroyed" actor. To reset an actor, you clear the storage with deleteAll(). While unintuitive, this leaves it up to the framework to implement.
Current Implementation: SharedWorker
Web Workers' SharedWorker is automatically destroyed when all ports are closed. This is not relevant to stateful serverless.
Proposal
Add a terminate method on the ServerlessWorker itself, leave it up to the frameworks to implement destroying. For example:
Connections & Messages
Current Implementation: Rivet
Both Rivet Actors & Durable Objects provide a way to serve requests to actors based on web standards.
Rivet provides flexible networking infrastructure, including UDP, TCP, and host networking. To remain widely compatible, Rivet relies on the Deno implementation of the fetch handler with Deno.serve.
Current Implementation: Cloudflare
Durable Objects supports a similar fetch handler, but also provides non-standard features like RPC.
Both rely on different implementations for WebSockets, though this handled gracefully by libraries like Hono's WebSocket helper.
There is a WinterTC proposal for a Sockets API, though I'm going to consider this out of the scope of this article since Cloudflare's implementation is not currently supported on Durable Objects.
Current Implementation: SharedWorker
However, Web Worker (SharedWorker) opts for using onconnect & port.onmessage like this:
Proposal
This could go two ways: lean into the existing WinterTC for ESM-style handlers like Durable Objects and Rivet or opt for a simpler & portable interface like Web Workers.
In my opinion, request/response should use ESM-style exports with the SharedWorker interface. This allows the simplicity of request/response & also enables full bidirectional streaming -- like a WebSocket but without the overhead.
Coincidentally, this also feels very similar to socket.io whose API has proven itself as flexible & easy to understand.
Storage
Current Implementations: Rivet & Durable Objects & Deno
Both Rivet and Durable Objects support a raw KV interface to access data stored on the actor itself.
While not specific to actors, Deno attempts to implement an abstract KV interface. However, this API is very opinionated to Deno Deploy and is by no means compatible across multiple clouds.
Why KV
Anything more (especially IndexedDB) is too complicated to expect cloud providers to implement correctly. localStorage has proven itself a simple & reliable key-value store that's lasted the test of time.
Frameworks can implement more advanced logic on top of key-value stores, just as they've done in the browser with localStorage.
Async
Regardless of what API this results in, it should be asynchronous. Cloudflare has gone as far as removing async code for their SQLite interface because they state it's fast enough to not require an async context; the KV API could likely be made as simple as something like the browser's localStorage by making each key a synchronous get. However, platforms all implement KV differently, so this may not make sense if attempting to provide maximum compatibility. Additionally, it would be impossible for compatibility layers to implement a KV API with an external medium if that medum requires an async operation to communicate with.
Strings vs Structured Clone
localStorage currently only supports strings, which is what most developers are used to.
However, both Rivet & Cloudflare Workers support natively storing data types that implement structured cloning which allows storing many types of data in a compact V8-compatible binary interface with high-performance serialization & deserialization.
If structured cloning was a protocol defined earlier, localStorage would likely support it natively. Whatever storage mechanism is chosen should support structured cloning.
A Word On Complexity
W3C has a history of inventing incredibly complicated standards for storage that are both (a) hard to understand as developers and (b) difficult to implement as a platform.
If you know how to use the IndexedDB API from memory, I'm impressed.
Additionally, Web SQL was an alternative standard that was deprecated because of its complexity.
Whatever the storage mechanism for ServerlessWorkers is, keep it simple, easy to implement, and easy to understand. Frameworks can always do the heavy lifting for you.
Concurrency & Input/Output Gates
Concurrency is difficult to implement correctly across multiple platforms.
Cloudflare Durable Objects intelligently prevents common storage race conditions on Durable Objects without transactions through a mechanism called input/output gates detailed here. This can be disabled with ctx.storage.get(/* key*/, { allowConcurrency: true }). Doing so will make the KV work like naive get/set without any extra functionality.
This is a controversial opinion, but I think that this behavior should be disabled by default and not part of a specification for a few reasons:
- Durable Object users almost never read from storage at runtime.
storage.getis called in the constructor andstorage.putis called when changed. - This behavior can be implemented at the framework level.
- This behavior is almost certainly going to be incorrectly implemented by vendors.
- Input/output gates do not work with WebSocket on Durable Objects already (please correct me if I'm wrong) and most developers aren't accounting for this.
postMessageandonmessageare closer to the Durable Object WebSocket behavior than the RPC behavior.
Keeping Scope Small
For the purpose of building a broader picture of what ServerlessWorker might look like in practice, I'm going to assume that storage is going to be part of this specification. However, I think it makes more sense to either (a) find an existing mature spec to use for storage or (b) define a separate spec that can work in contexts outside of ServerlessWorker.
Proposal
Provide a dead simple async structured clone-based KV API and let the platforms provide extra configs for concurrency. For example:
Scheduling
Current Implementations
A core part of ServerlessWorkers is to be able to run a function at an arbitrary timestamp.
Cloudflare provides a simple setAlarm API that has a single alarm. If you already have an alarm, it will override that alarm. I like this API since it's significantly simpler than setInterval and setTimeout and lets frameworks provide more advanced APIs, such as CRONs.
Proposal
Provide an API similar to Cloudflare's setAlarm. For example:
Sleeping & Upgrading & Host Migrations
A core advantage of ServerlessWorkers to something like Kubernetes jobs or other container-based stateful workloads: ServerlessWorkers can automatically sleep when there are no active operations and wake upon either fetch or alarm.
However, ServerlessWorker has to address specific edge cases when there are tasks that need to run in the background before being put to sleep.
Current Implementation: Rivet
Rivet mimics Unix behavior by sending a SIGINT signal to the process when it plans to go to sleep. Your application is given time to clean up any work and restart gracefully when it's ready. This provides compatibility for a wide range of existing frameworks that implement the Node.js or Deno shutdown handler.
Current Implementation: Durable Objects
Durable Objects provides waitUntil. My understanding is this is effectively a noop since (see note). However, I like the waitUntil API since it provides a JavaScript-y way of forcing the actor to stay awake.
Proposal
Provide an API similar to Durable Objects waitUntil. The provider can decide the maximum duration for this function. For example:
Handling Backpressure
Backpressure is a core problem in every distributed system and should always be handled carefully by developers to handle load gracefully.
Current Implementation: Rivet
Rivet provides low-level primitives to the developer, so it's up to the developer to handle backpressure accordingly. An overloaded actor without any special backpressure handling will saturate the CPU.
Current Implementation: Durable Objects
Durable Objects throw an error with the .overloaded property set to true when making requests to a Durable Object that cannot accept more requests.
Proposal
Define an error type that can be used by developers to handle backpressure gracefully.
Security Model
Proposal
ServerlessWorker should rely on the existing work in WinterTC. They are secured via these attributes:
- Fetch Handler: Stateful
ServerlessWorkers are only accessible through the stateless serverless fetch handler defined in WinterTC. This creates a protected gateway where all requests are authenticated and authorized before reaching anyServerlessWorker. - Isolation Boundaries: Each
ServerlessWorkerruns in its own isolated environment, similar to Web Workers, preventing cross-worker data access without explicit communication channels. - No Direct Network Access:
ServerlessWorkers cannot be directly addressed from the public internet. All communication flows through the fetch handler, which can implement rate limiting, validation, and other security controls.
The downside of relying on the fetch handler is that it may restrict who can implement ServerlessWorker. For example, there are many container orchestration platforms that may be able to implement the worker part of ServerlessWorker, but cannot implement the fetch handler. I don't think this is an issue, since including these technologies that don't already comply to WinterTC would make it too broad to be effective.
Out Of Scope
Items out of the scope for this spec:
- Locality: Cloudflare & Rivet both have notions of where actors run, though the default is to run nearest where the request is coming from. This will likely end up as a platform-specific feature when constructing
ServerlessWorker. - Supervisors: Traditional actor runtimes use "supervisors" to automatically restart crashed actors.
ServerlessWorkercannot crash, and instead will automatically log and disregard thrown errors -- similar to service workers. - SQLite Storage: Many serious use cases of Durable Objects rely on SQLite. This is out of the scope for this web standard.
- Versioning: Cloudflare and Rivet each have significantly different ways of implementing versioning. Rivet is more like AWS AMI, while Cloudflare uses a simpler but less flexible version history.
- Upgrades & Rolling Deploys: Leave it up to the platform to decide what code is running. Under the hood, the Rivet implementation of this standard would automatically call
actors.upgrade - Logging: Leave this up to the platform to decide how to ship logs.
Full Examples
Rate Limiter
This example demonstrates building a rate limit.
Pub/Sub Server
This example demonstrates a simple pub/sub system where each topic is its own serverless worker with connected clients.
Simple Chat Room
This example demonstrates a simple chat room implementation with message persistence.
Redis-Like Server
This example demonstrates a minimalistic Redis-like key-value store server with get, set, and delete operations.
More Thought Required
Data Migrations
WinterTC is great specification for stateless serverless since migrating providers is as simple as updating a DNS record.
However, stateful serverless is significantly different since this spec is effectively defining a database, since ServerlessWorkers have persistent storage.
If the whole point of defining a common specification for stateful serverless is to encourage companies to adopt new technologies, then they'll also need assurances on their ability to migrate between providers. For example, Postgres provides the ability to use logical replication for live migrations and is used frequently.
Storage
The storage is the most rough section of this spec. It probably justifies its own spec.
Connection Interruptions
SharedWorker connections cannot be interrupted. Can ServerlessWorker connections be interrupted? What happens if they are?
Next Steps
We uploaded this proposal to GitHub for feedback and iteration. Once there's more momentum, I hope to move this out of the rivet-gg organization in to an official W3C process.
Feedback On GitHub
Please add feedback as a issue or pull request on the proposal GitHub.
Reference Implementation
Once a general specification is implemented, a reference specification is trivial to implement on any of the providers previously mentioned. A compatibility layer could be implemented on the existing work with Rivet drivers.
Survey: Help Shape the Specification
If you are either (a) a user of Durable Objects/Rivet actors or (b) want to aid in the direction, it'd be helpful to take the time to answer these questions as a GitHub issue on the proposal:
- Do we attempt to specify existing APIs or implement based on existing work by W3C? This spec aims to build on patterns already defined by W3C, however it might make sense to stick to better documenting overlap between existing providers (currently only Durable Objects & Rivet as far as I know). My understanding is WinterTC attempted to create a spec that matched existing APIs. I'd be happy to rewrite this spec based on the
fetchAPI if the answer to this is yes. - What are the most common hesitations for companies adopting stateful serverless? Is there something this spec can address?
- What are the most common problems with stateful serverless that contributes to cognitive load? Does the simplicity of this spec help address that?
- What reference design patterns should we be designing for? The examples attached attempt to provide a very basic overview of common patterns on Durable Objects, but does not cover use cases like worker-worker communication.
- How should storage be represented? This spec proposes using a simple KV. This storage mechanism might be too restrictive, or we might not want to write a spec for storage altogether and keep
ServerlessWorkervery simple. It may make sense to leverage an existing storage spec or write a new separate storage spec that is combined with this. - Should this be broader than web technologies? This spec makes the assumption it's part of W3C and leverages web technologies. However, there are a few container platforms that do not use web technologies which might fall under this scope.
- Should this spec care about regions?
ServerlessWorkershine when they run at the edge. Should they have a default for configuring locations, similar to Rivet and Cloudflare?
Thanks to LambrosPetrou, firtozb, uripont_, and p_mbanugo for feedback on the initial document.