
SQLite-on-the-Server Is Misunderstood: Better At Hyper-Scale Than Micro-Scale
We're Rivet, a new open-source, self-hostable serverless platform. We've been in the weeds with SQLite-on-the-server recently and – boy – do we have a lot of thoughts to share. Give us a star on GitHub, we'll be sharing a lot more about SQLite soon!
There's been a lot of discussion recently about the pros and cons of SQLite on the server. After reading many of these conversations, I realized that my perspective on the power of SQLite-on-the-server is lopsided from popular opinion: SQLite's strengths really shine at scale, instead of with small hobbyist deployments that it's frequently referenced in.
Background
Before jumping in to my perspective on the benefits of SQLite at scale, it's helpful to understand some background on SQLite-on-the-server for micro-scale apps.
Why Developers Love SQLite for Micro-Scale Deployments
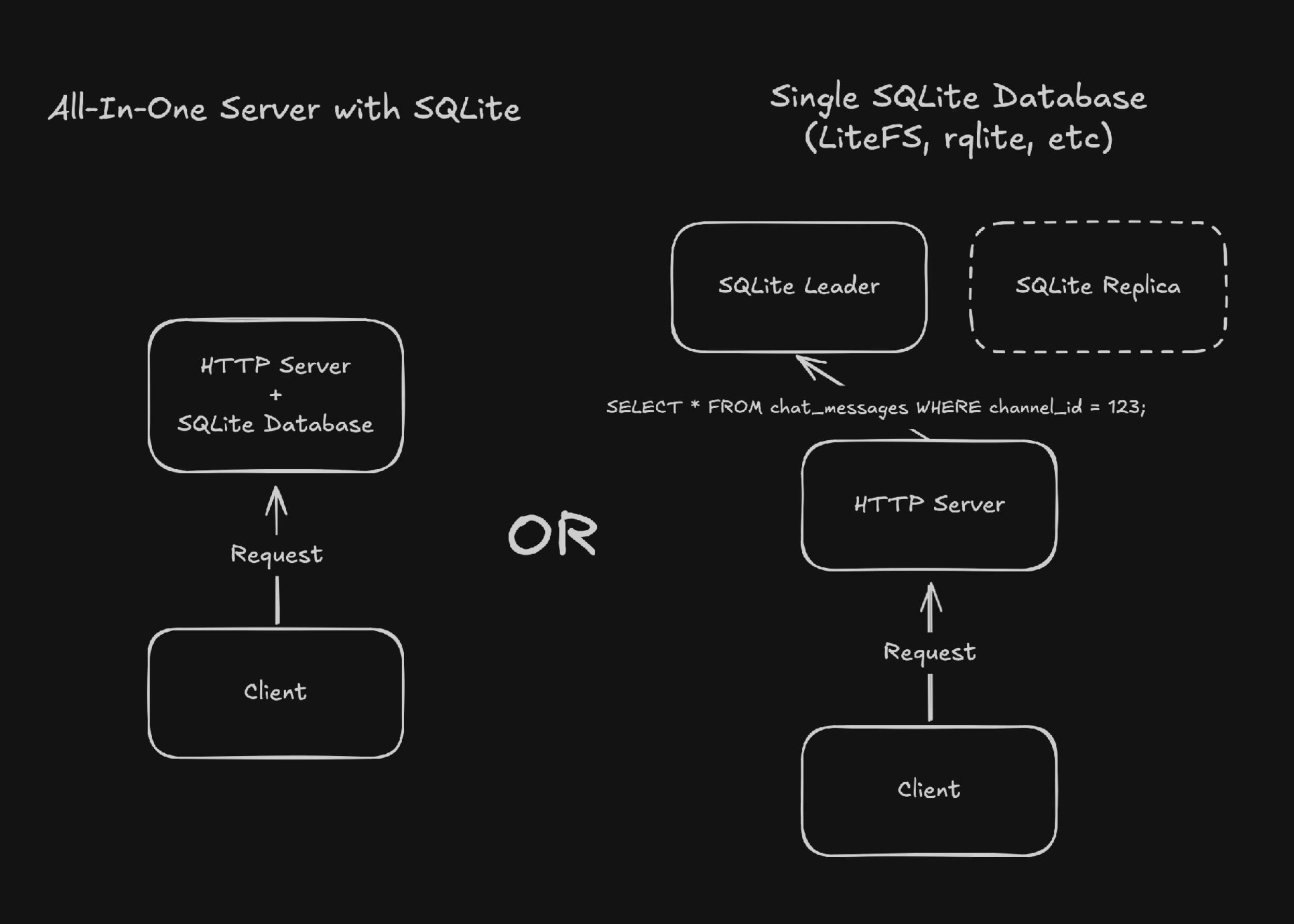
Most developers consider server-side SQLite a simple, cost-effective choice for small-scale applications. It's often valued for:
- Low infrastructure costs: No need for separate database servers—just a single file.
- Seamless development and testing: The same database file can be used across client and server.
- Minimal management overhead: No complex configurations or database daemons.
- Proven reliability: It's been around forever. It's the world's most widely deployed database and built to withstand battleships getting blown to bits.
These characteristics make SQLite an attractive option for personal projects, lightweight applications, and prototypes.
Tools for SQLite-on-the-server
Tools like LiteFS, Litestream, rqlite, Dqlite, and Bedrock enhance SQLite with replication and high availability for micro-scale deployments.
However, this post focuses on Cloudflare Durable Objects and Turso to highlight the often-overlooked advantages of SQLite at scale.
Databases at Hyper-Scale Today: Sharded Databases & Partitioning Keys
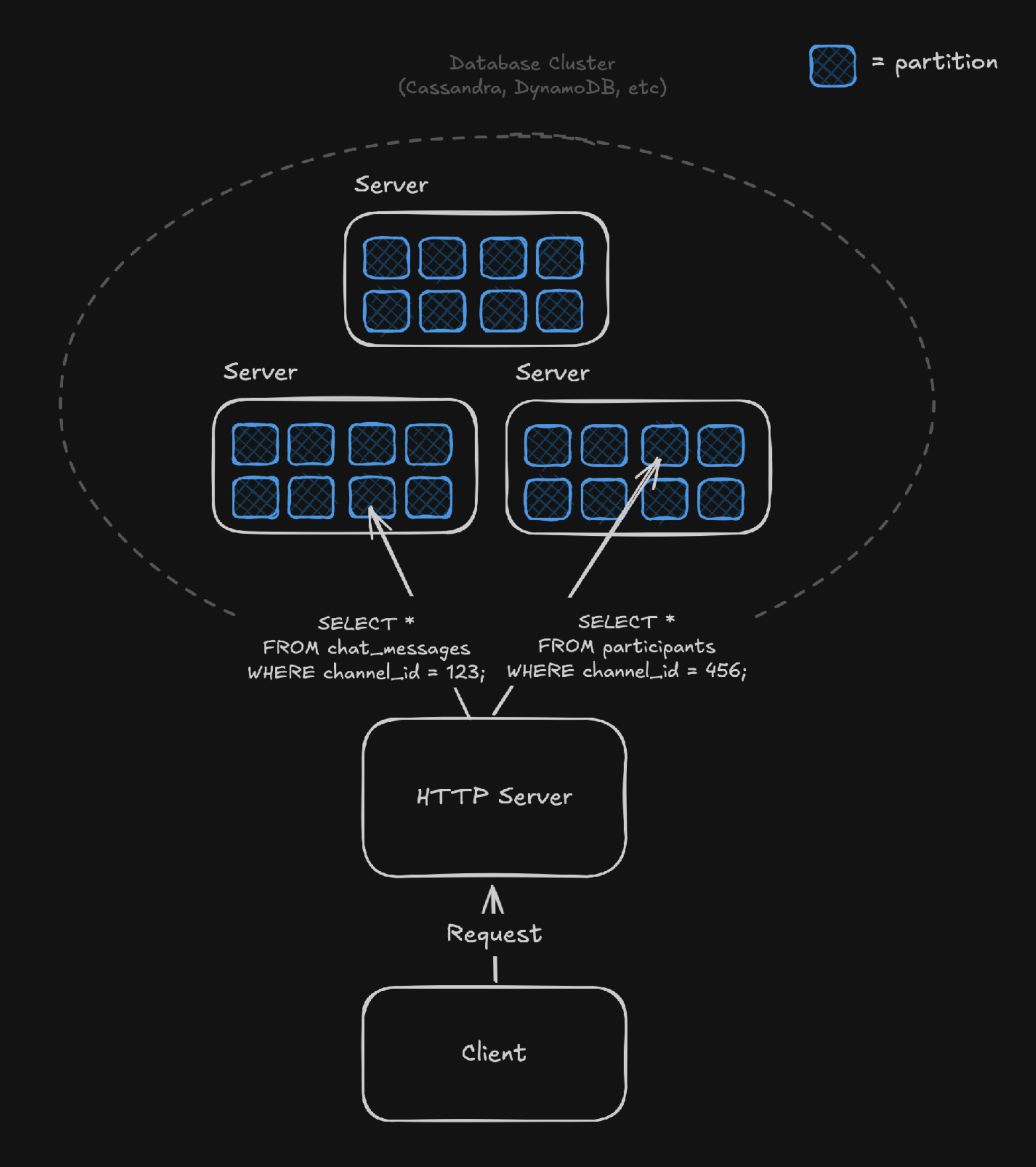
In high-scale systems, companies frequently struggle scaling databases like Postgres or MySQL. Instead, they often turn to sharded databases such as Cassandra, ScyllaDB, DynamoDB, Vitess (sharded MySQL), and Citus (sharded Postgres).
These systems use partitioning keys to co-locate related & similarly structured data. For example, a typical chat application on Cassandra might define:
To query messages from this partition, you could write:
Benefits of Sharded Databases
Sharded databases power almost every large tech company because they provide:
- Efficient batch reads with data grouped in the same partition.
- Horizontal scalability by partitioning data across nodes.
- Optimized writes for high-ingestion workloads
Apple runs the world's largest known number of Cassandra/ScyllaDB instances with roughly 300,000 nodes as of 2022. Almost all large companies have shared that they also run massive clusters of partitioned databases in the thousands of nodes.
Challenges with Current Partitioning Solutions
While partitioning strategies improve scalability, they introduce significant challenges:
- Rigid schemas: Unlike Postgres or MySQL, the schema must exactly match the intended query patterns exactly, limiting flexibility.
- Complex schema changes: Adding a new index or relation requires significant operational overhead to create & populate a new table in a live system.
- Complex cross-partition operations: Enforcing ACID properties across partitions is difficult. Companies often resort to complicated two-phase commits or design with an acceptable level of data inconsistency.
- Data inconsistency: Without strong constraints between tables & partitions, data frequently becomes "dirty" because of interrupted transactions or failure to propagate changes.
Enter SQLite at Scale: Cloudflare Durable Objects & Turso
Cloudflare Durable Objects and Turso demonstrate how SQLite will change how hyper-scale applications may be architected in the future.
These databases provide:
- Dynamic scaling: Instantly provision databases per entity, reducing infrastructure complexity.
- Infinite, cheap databases: Similar to partitions, you can spawn an infinite number of SQLite databases because they are incredibly cheap to create & manage.
- Global distribution: Databases are placed closer to users, improving query performance.
- Built-in replication and durability: Unlike traditional SQLite, these services replicate data across multiple regions for high availability.
A Better Hyper-Scale Database: SQLite Database Per Partition
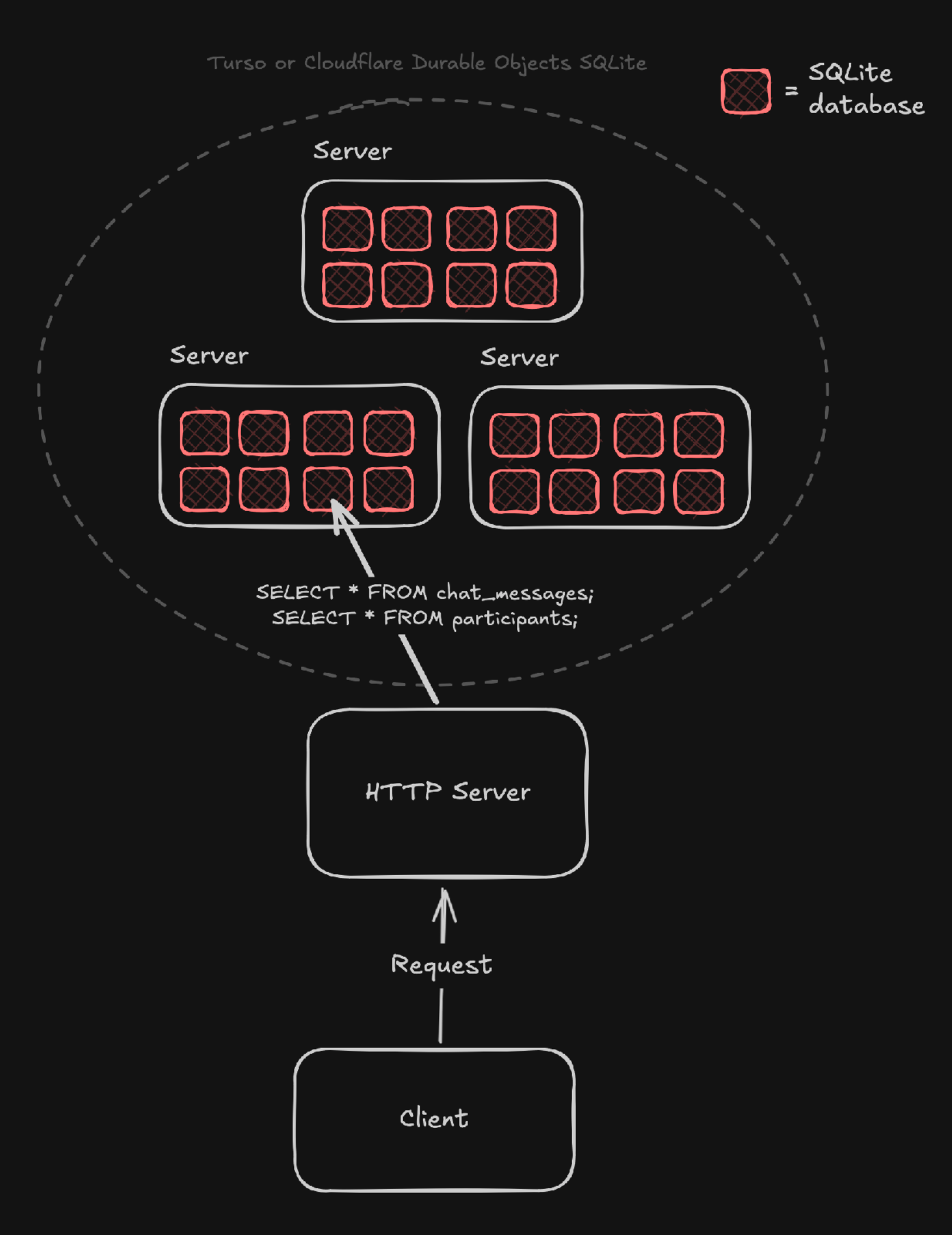
Using SQLite with Cloudflare Durable Objects & Turso allows defining databases per entity, effectively replacing partitioning keys.
Instead of storing chat logs in a single partition, each chat channel can have its own SQLite database that also includes more tables, like participants and reactions. A sample schema could look like this:
From Cloudflare Durable Objects or Turso, this SQLite partition database could be queried like this:
Benefits of SQLite-Per-Partition
- Local ACID transactions: Complex SQL queries can be within each partition without cross-partition complexities.
- Efficient I/O: SQLite enables performing complex queries within the partition with very high performance.
- Leverage existing SQLite extensions: SQLite has a rich ecosystem of existing extensions, such as FTS5, JSON1, R*Tree, and SpatiaLite.
- Full Power of SQL migrations: SQLite provides the full power of SQL migrations & leveraging existing migrations tools such as Drizzle & Prisma.
- Lazy schema migrations: Changing schema is tricky at scale. Assuming your migrations are lightweight, they can be executed on demand after the SQLite database is opened at the cost of a slightly higher p99 after deploys.
Who are the Turso founders? It's no coincidence that the founders of Turso used to work at ScyllaDB, where they saw firsthand the complexities of large-scale partitioned databases on a daily basis.
Where SQLite Still Falls Short
Despite its benefits, SQLite at scale presents a few challenges:
- Lack of an open-source, self-hosted solution.
- No built-in cross-database querying, making complex analytics difficult without a dedicated data lake.
- Limited database tooling, such as SQL browsers, ETL pipelines, monitoring, and backups. StarbaseDB is addressing this for Cloudflare Durable Objects with SQLite.
- Non-standard protocols for communicating with SQLite-on-the-server. In contrast, PostgreSQL, MySQL, and Cassandra all have a well standardized wire protocols across all cloud providers that has led to a rich community of tools.
- There are no case studies like Cassandra & DynamoDB have of using SQLite with this architecture at hyper-scale. This will change with time.
Conclusion
SQLite on the server is more than a lightweight solution for small deployments – it's an increasingly viable alternative to traditional partitioned databases. By leveraging SQLite-per-partition solutions like Turso and Durable Objects, developers gain rich SQL capabilities, ACID compliance, and significant operational advantages.